“Impact Evaluation Landscape”1 mentioned that within the crypto ecosystem, there is a growing movement to evaluate impacts to measure what results different projects are achieving and how. In the crypto ecosystem, a wide range of activities are undertaken—open source software, hackathons, conferences, grant programs, and more. These initiatives are often funded by DAOs or foundations and then executed their projects. However, because each project has different goals, it is currently difficult to understand what outcomes they actually achieve. As a result, there is a tendency to fund projects whose actual results are unclear, or whose effectiveness lacks convincing evidence. This tendency leads to the depletion of DAO funds, so funding mechanisms should be more effective and efficient. In the crypto ecosystem, some actors are working on impact evaluation (or outcome measurement) under the view that funding should be based on measured outcomes. In other words, efforts are proliferating to examine questions like “Which projects (public goods) deserve more funding?” and “Were these projects (public goods) truly effective for a particular ecosystem?”


However, under current conditions, evaluating impacts is extremely difficult. The reason is that the groundwork for evaluating impacts is not yet in place. Impact is “the difference between the outcome produced by an intervention and the outcome that would have occurred without the intervention,” and impact evaluation often refers to “measuring that difference in outcomes.” As a premise for impact evaluation, it is important to clearly distinguish outputs from outcomes. In general, outputs (e.g., number of event participants, newly created products) are easier to measure and track. But to truly assess the effectiveness of an intervention, we must prioritize outcomes (e.g., behavioral changes among participants after an event), which require more complex data collection and analysis. It becomes crucial to define a causal hypothesis of how outputs lead to specific outcomes, and to collect data to test it. If the hypothesis is supported, additional resources are invested; if refuted, the plan is reconsidered. In short, to evaluate impacts, we must hypothesize which outputs lead to which outcomes, and the supporting evidence becomes crucial. Grounded in hypotheses and evidence, this way of practicing like impact evaluation is an approach known as Evidence-based Practice (EBP)2.
Note:
- Output: The immediate deliverables or results of an initiative
- Outcome: The changes in behavior or state brought about by those outputs
It is reasonable to implement EBP for digital public goods including the crypto ecosystem. One of the functions of DAOs and foundations is to fund digital public goods themselves or projects that support them (such as grant programs and educational programs). In this respect, they can be seen as analogous to nation states that maintain and provide public goods. In recent years, governments have emphasized EBP and actively pursued Evidence-based Policy Making (EBPM) — that is, making policy decisions grounded in evidence. Just as governments are introducing EBPM, introducing evidence-based decision-making (EBP) within DAOs, foundations, and OSS communities that maintain and provide digital public goods is a reasonable direction for making funding allocations more rational.
However, in the digital public goods ecosystem, the “Evidence Layer” required to do evidence-based work is still underdeveloped. A robust Evidence Layer is essential for the healthy development of digital public goods and for effective public goods funding. For example, whether distributing funds, evaluating the impact of funders or grantees, or developing OSS, we will need an ecosystem that enables the use of evidence—the “Evidence Layer”—across all these scenarios. In this post, I discuss why using evidence matters for digital public goods and what effects it could bring.
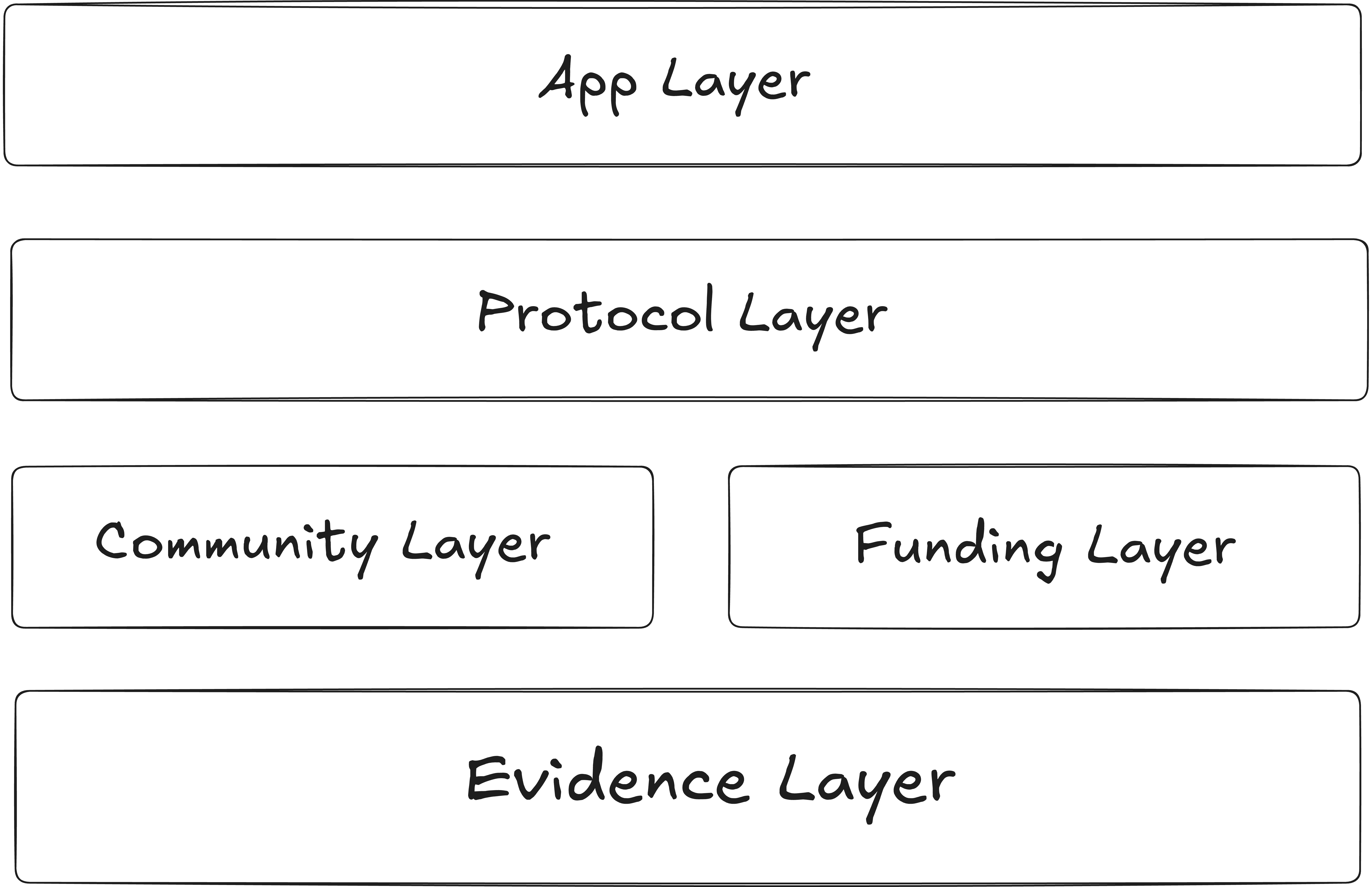
Evidence 101
Even outside digital public goods, EBP faces many challenges in general. As one of challenges, it is commonly thought that EBP proceeds through the processes of “Create,” “Communicate,” and “Utilize” evidence.3 “Creating evidence” means that researchers conduct impact evaluations through using methods such as difference-in-differences analysis, propensity score matching, or randomized controlled trials (RCTs) to identify the causal relationship between an intervention and its outcomes. By contrast, “utilizing evidence” means applying the results (evidence) of scientific analysis to actual policies, and leveraging them for accountability and decision-making. So what does it mean to “communicate evidence”? “Communicating evidence” is about bridging scientific findings (evidence) so that they can be used in practice. Because scientific findings are often highly specialized, it is difficult to apply them in real-world contexts. Not everyone can tell whether a given analysis is rigorous or whether it uses trustworthy data. A concrete example of “communicating evidence” is the Cochrane Library. This collection of databases (evidence bank) that gathers and summarizes reliable evidence on the effects of medical interventions, is useful in clinical settings when referencing evidence, and thus plays the role of “communicating evidence.”
Here, let’s classify efforts in the crypto ecosystem along the lines of “creating,” “communicating,” and “utilizing” evidence.
- “Create”: Opensource Observer, Eval.Science, GainForest, KarmaGAP, Impact Garden
- “Communicate”: MUSE, Hypercerts
- “Utilize”: Optimism, Filecoin, VoiceDeck, Drips
Since 2023, efforts to evaluate impacts have accelerated, but the current focus is mainly on “creating evidence.” Indeed, the grant analysis we conducted in the past4 would fall under “creating evidence.” On the other hand, as an initiative to “utilize” evidence, Optimism, which advocates the principle of Retro Funding5, is actively practicing it, but across the ecosystem, we can still say it is developing. In EBP for the crypto ecosystem, activity is vibrant on the “creation” side, whereas initiatives for “utilization” are relatively scarce. This challenge is shared with EBP more broadly. In other words, to make EBP easier to do, it is undoubtedly important to make scientific knowledge usable by anyone—that is, to strengthen initiatives for “communicating evidence.”
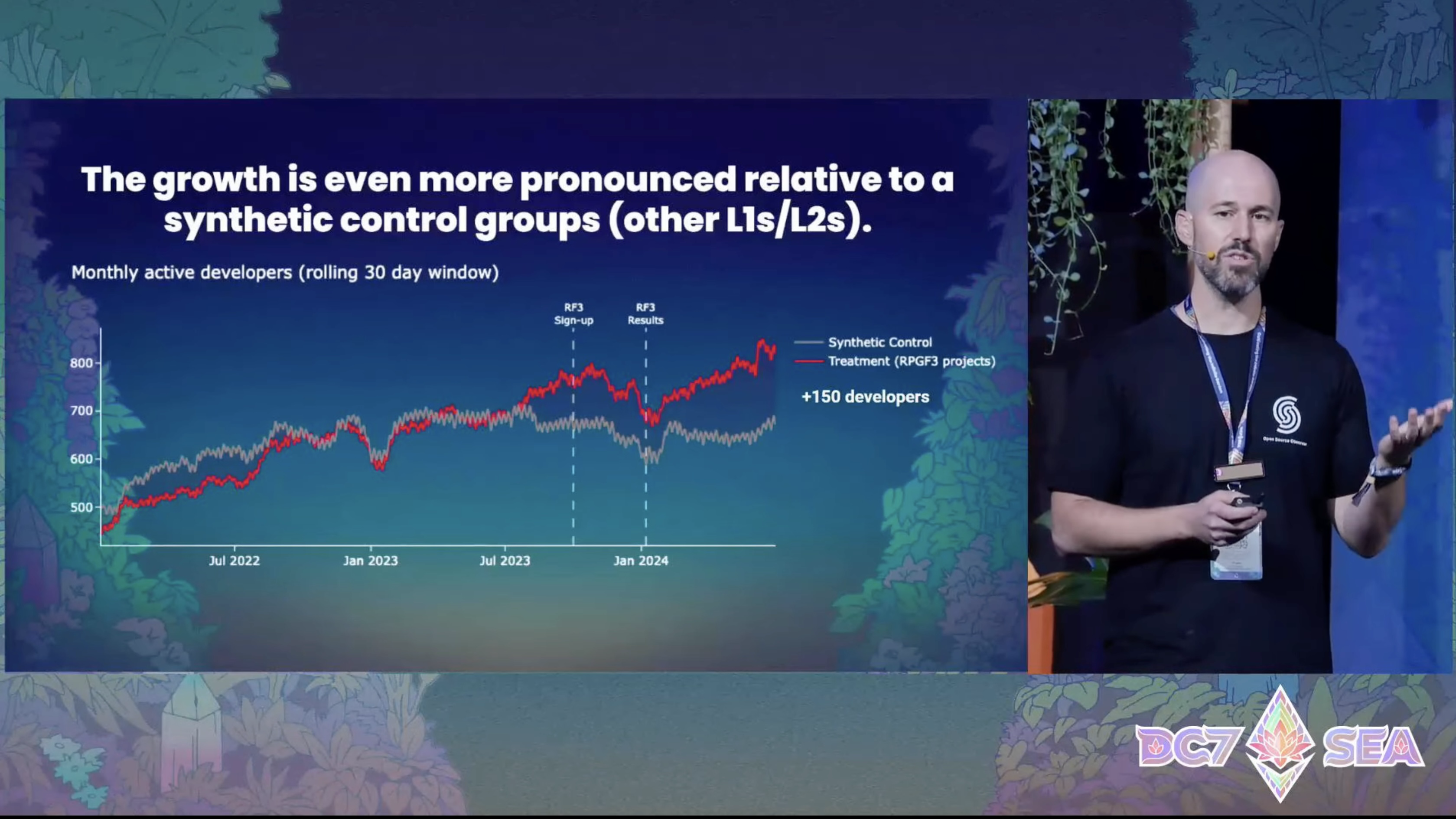
"Evidence Communication"
One initiative for “communicating evidence” is Hypercerts, a token standard for impact certificates. By using Hypercerts, projects can receive multiple evaluations, including self-reports, and establish or verify claims about a project’s impact. Projects that use Hypercerts can publicly display the impact they have generated (the effect attributable to their intervention). In that sense, it plays a “communication” role by enabling measured impact (“creating evidence”) to be leveraged in funding decisions (“utilizing evidence”).

Other precedents for “communicating evidence” include the aforementioned Cochrane Library, an evidence bank that compiles “high-quality evidence” useful for medical decision-making. It centrally provides the latest and most reliable evidence, aiming to make evidence-based decisions easier for clinicians, policymakers, and patients. There is also CHAOSS, led by the Linux Foundation, a project that compiles metrics reflecting the health of OSS communities. These platforms certainly mediate between those who produce evidence and metrics and those who use them; however, they remain insufficient when it comes to how to use them in practice.
MUSE — Modular Stack of Evidence
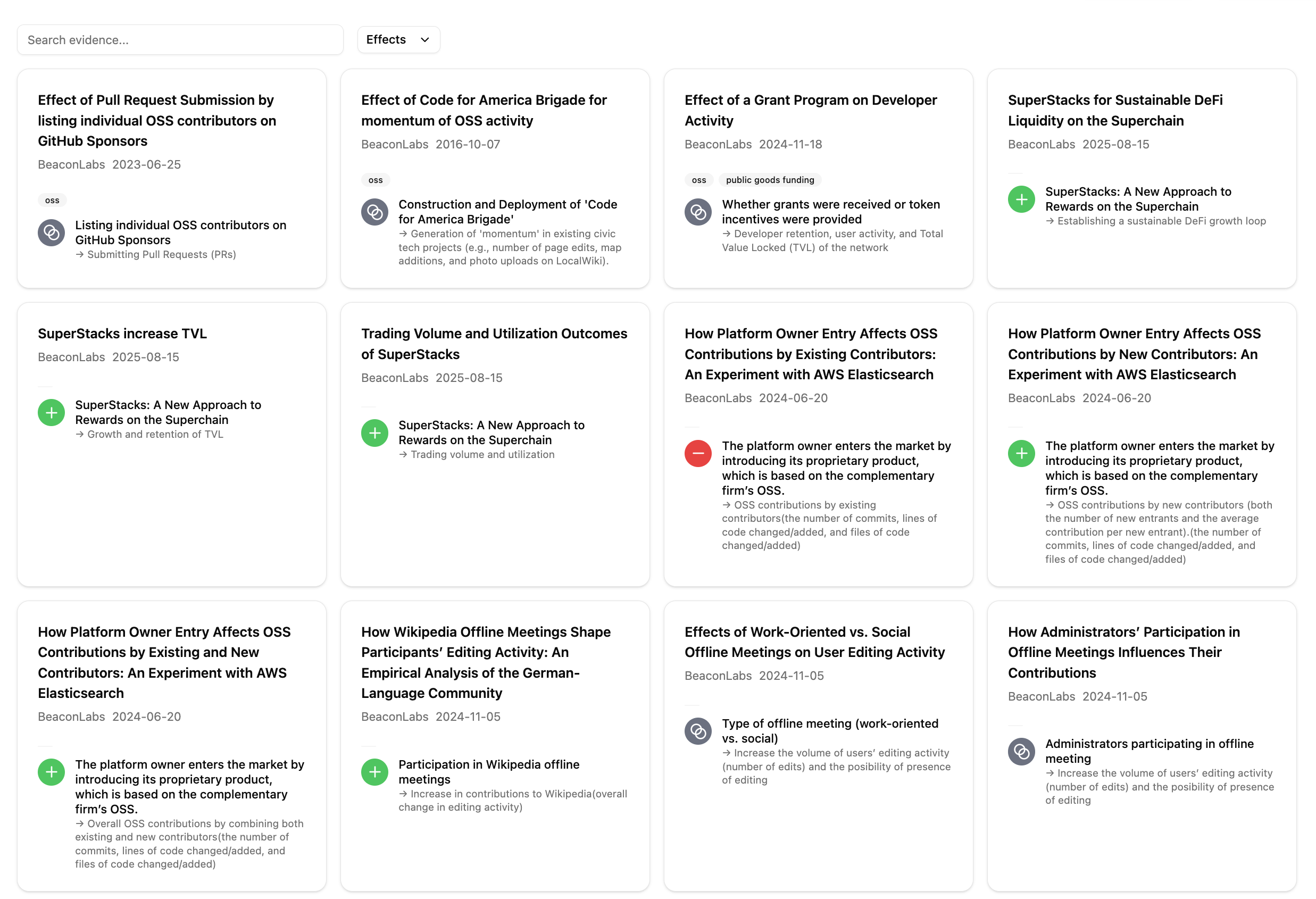
We, Beacon Labs are also striving to contribute to “communicating evidence” through an OSS project called MUSE (Modular Stack of Evidence). MUSE is an EBP support system specifically for digital public goods, led by Beacon Labs, that enables the registration, use, and strengthening of evidence. As noted above, traditional database collections are highly useful, but their high degree of specialization has made them difficult to use. MUSE adopts a composable and open-source design, and addresses this challenge by focusing on bridging evidence to implementation rather than merely gathering it. What MUSE emphasizes is to build a “logic model (implementation plan)” through using structured evidence. A logic model is a diagram that organizes, as a causal flow, what resources an initiative (program, project, or policy) uses, what activities it implements, and what outcomes it leads to. In MUSE, we combine interventions, indicators, and outcomes with evidence, explicitly representing causal hypotheses as logic models and making them easy to construct and implement. 3 main components of MUSE are integrated seamlessly to enable the production of evidence-based logic models:
- Curation (Registering evidence): Aggregate evidence from around the world and structure it into reusable formats.
- Citation (Using evidence): Combine structured evidence to easily construct and implement logic models (implementation plans) that link interventions, indicators, and outcomes.
- Cultivation (Strengthening evidence): Strengthen existing evidence and generate new insights through implementation-data feedback and meta-analyses.
This mechanism becomes more powerful when integrated with Hypercerts. Normally, to issue Hypercerts does not require submitting logic models, but by going through MUSE, you can issue one with building an evidence-based logic model. As a result, MUSE complements Hypercerts’ functionality and makes it easier to apply transparent impact evaluation for a practice. In this sense, the “communicating evidence” function is being expanded.
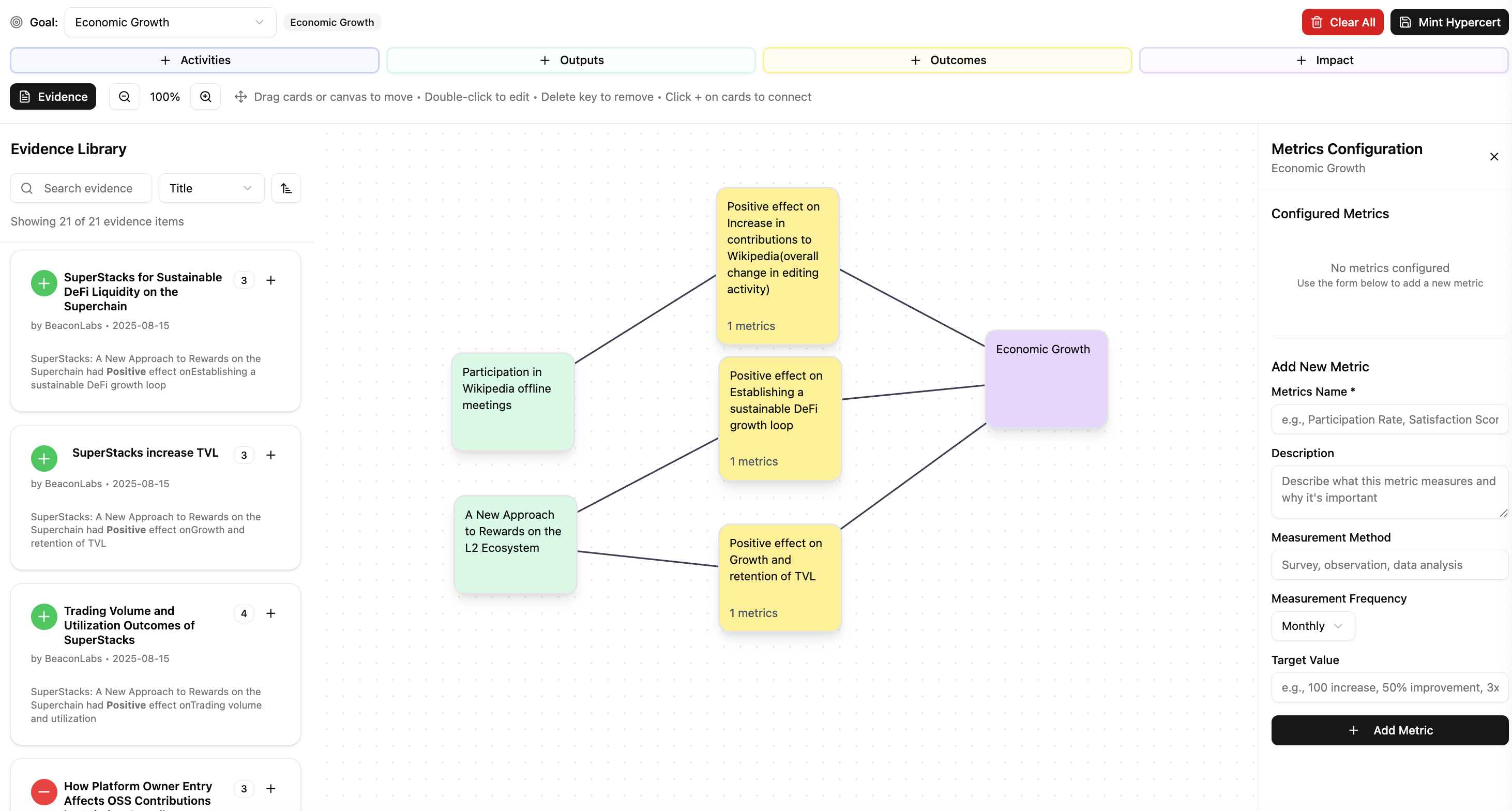
Evidence Layer: A Feedback Loop for Digital Public Goods
Here’s a concrete flow of how the Evidence Layer functions, or how evidence is used (how EBP is working) when MUSE is introduced. Consider a case where we want to run a PDCA cycle for digital public goods. A brief explanation of PDCA: In P (Plan), you define your desired end-state with numbers and deadlines, assess the current situation, formulate issues and hypotheses, and decide who will do what by when and how it will be measured. Next, in D (Do), you execute the plan, starting with small experiments, organizing procedures, and recording data—both where things go as expected and where they do not. In C (Check), you verify results against indicators, analyze the gap from targets, adherence to processes, and whether the hypotheses held up. Finally, in A (Act), you standardize what worked, update hypotheses based on the causes of what didn’t, and feed this into the next P(Plan). Repeating this elevates personal methods into organizational systems and incrementally improves quality and outcomes.
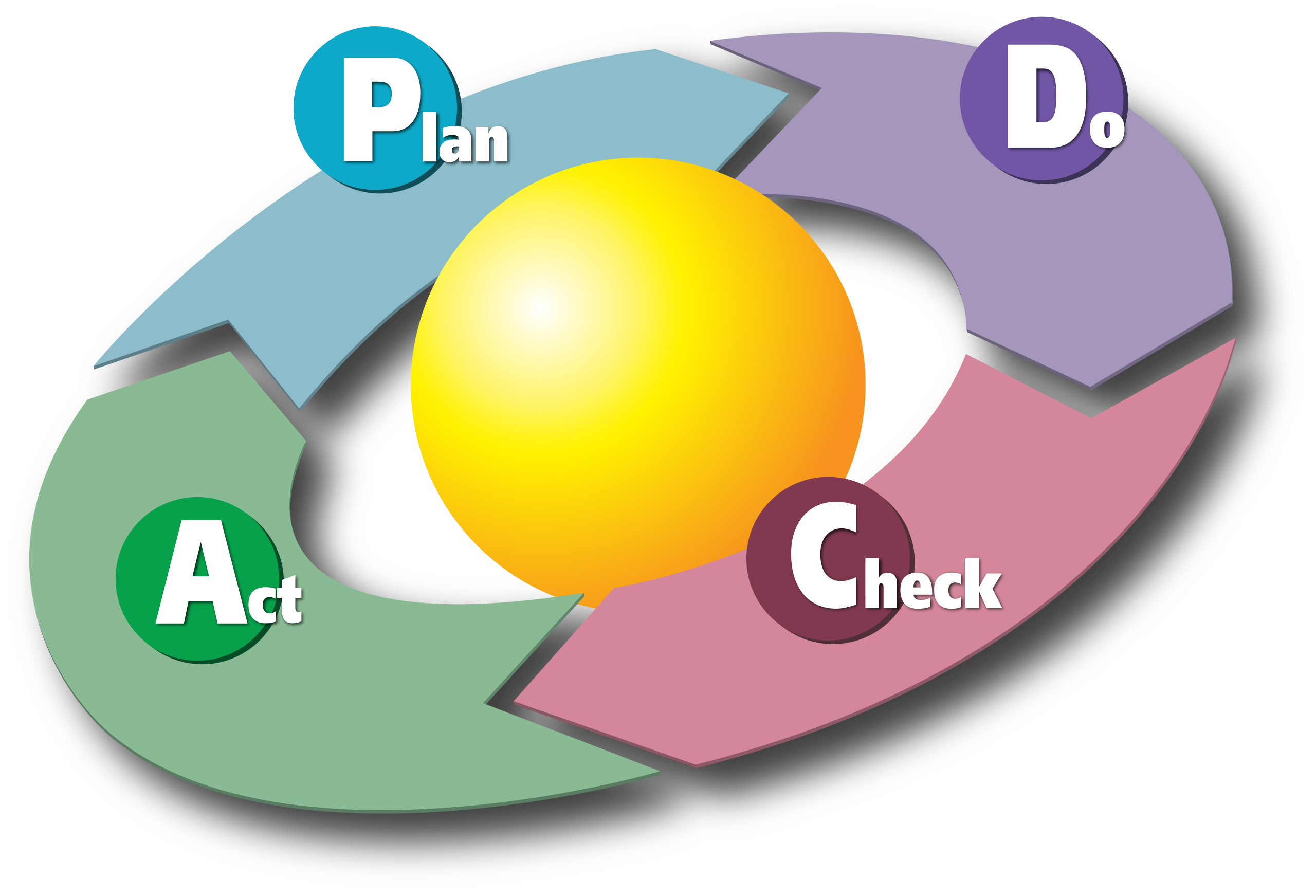
When mapping EBP onto the PDCA cycle, it becomes clear that the P component is lacking. For example, the process often works as follows: develop an OSS project (D), have an impact evaluator who “creates evidence” assess the project (C), and use the findings for improvement (A). The system is not set up to start projects with evidence-based planning at the P stage. As noted earlier, OSS communities tend to be active in D, and in recent years C has gained importance. But, you cannot properly conduct C without P. For impact evaluation (C), it’s important first to address P.
This corresponds to the situation pointed out at the beginning: “evaluating impacts is extremely difficult.” Because MUSE expresses causal hypotheses as logic models, to use MUSE can also help lay the groundwork necessary for impact evaluation.
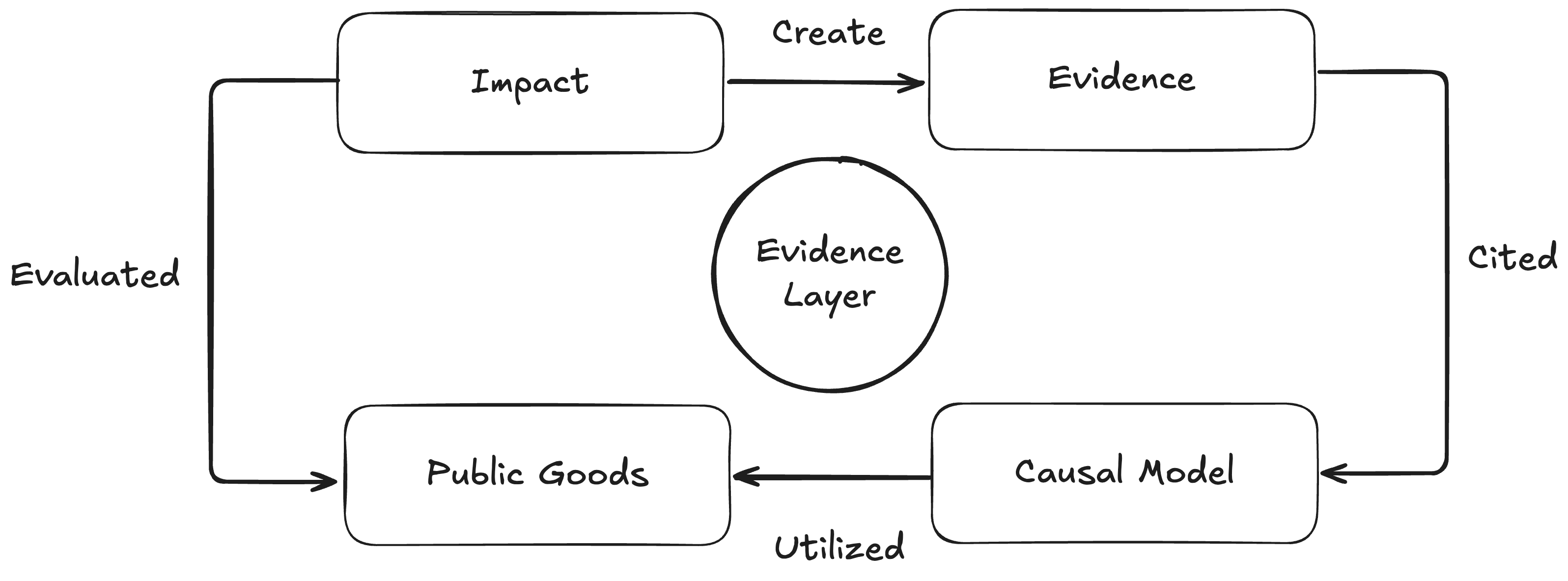
Evidence generated is curated by MUSE, and project teams refer to MUSE and create logic models. Hypercerts are then issued, and the project is executed. After some time, based on the logic model created via MUSE, impact evaluators measure the project’s effects. The measured effects are reflected in Hypercerts and used for feedback, while also being stored in MUSE as new evidence. By running this kind of feedback loop, we believe we can build a healthier digital public goods ecosystem.
Evidence Becomes a Beacon for the World
Here, I’ll share our thoughts on what kind of world the establishment of the Evidence Layer could lead to.
Retro Funding vs. Pro Funding
Retro Funding was founded on a principle proposed by Vitalik: “It’s easier to agree on what has been useful than on what will be useful.”5 However, a World Bank report states that prospective evaluations tend to produce more credible results than retrospective evaluations.6 In other words, this suggests that Pro Funding (Prospective Funding), which allocates funds in advance, may be “easier to agree on / easier to implement” than Retro Funding. The main reason is that prospective evaluations design causal models (which data to collect, how to evaluate) before the intervention begins and can secure baseline data. With a baseline, you can confirm that the treatment groups and control groups are statistically similar at the start. Retrospective evaluations, by contrast, often lack baseline data because they are conducted after implementation. As a result, they must rely on quasi-experimental methods (estimating causal effects from observational data) that depend on stronger assumptions, making the evidence more open to interpretation.
Moreover, if you can design a prospective evaluation, you can estimate the counterfactual, which is the outcome that would have been observed if the intervention had not occurred. Impact evaluation investigates the difference between the effect of a given intervention and the effect that would have occurred without it, and must exclude the possibility that factors other than the intervention (confounders) produced the observed effect. To evaluate impact accurately, estimating the counterfactual is crucial. However, retrospective evaluations struggle to estimate counterfactuals. Unless evaluation is embedded from the outset, many programs do not collect baseline data, and once the program starts, it’s too late to collect it. Evaluators often have limited information, making it difficult to analyze whether the program was implemented properly and whether participants actually benefited.

If each digital public good can build a causal model, the opportunity for Pro Funding will emerge. By designing projects in an evidence-based manner, it will likely become easier to secure validity, accountability, and persuasion from communities for prospectively raising funds. Then, after implementation, conducting impact evaluation (outcome measurement) would enable fundraising proportionate to the degree of achievement. In other words, by creating evidence-based logic models, we can have ways of Evidence-based Pro Funding and Outcome-based Retro Funding.
Toward Open Science
Evidence Layer also leads to open science. Open science is a comprehensive concept that makes the outputs and processes of scientific research open not only to researchers but also to the general public, enabling anyone to access and participate. Developers of digital public goods including OSS contributors work daily on a variety of products, and there are organizations that fund them. Meanwhile, scientists produce various scientific findings—evidence—through their research activities. The problem is that those who contribute to maintaining and providing digital public goods (developers and funders) are not well connected to the scientists. The Evidence Layer is the foundation for making scientific knowledge usable in the field, and initiatives like MUSE and Hypercerts which contribute to “communicating evidence” will make science more open, practiced, and applied.
Evidence and Plurality
Beacon Labs has declared a vision of a world that respects diverse values.7 We believe, in order to achieve this vision, we need designs that don't depend on a single value standard or decision-making mechanism. Even though digital public goods each have different goals, funding mechanisms tend to become uniform. For example, in public goods funding, Quadratic Funding (QF), which is actually incorporating mechanisms such as clustering and Sybil resistance, ultimately relies on a given algorithm to determine disbursement amounts. Because QF allocates more funds to projects supported by a larger number of people, even with small contributions, popular projects tend to attract more funds.8 While algorithmic dependence can ensure transparency and fairness, it may also lead to the unification of values and make it difficult to fully reflect the characteristics of projects with diverse objectives and methodologies. This observation connects to the “paradox of Plurality” discussed in “Instrumentalized Plurality: Dialectic of Enlightenment fixes Plurality.”9
Plurality, which originally aimed to reflect diverse values, has become "instrumentalized" by rationalizing the pursuit of democratization, leading to the unification of values. To escape from this rationalized system, paradoxically, we may need multiple unified sets of values.
Pursuing Plurality through mechanisms and algorithms may paradoxically result in a singular value, or a fixed plurality. If we are to realize Plurality, paradoxically, we may need to maintain our own intentionally “biased” value. For example, although QF is regarded as a kind of plurality, relying on “pluralistic” algorithm defined by QF isn't necessarily pluralistic. To be truly pluralistic, multifaceted values including different from those of QF will need to coexist.
A powerful means for introducing such multifaceted values is evidence. As the Evidence Layer expands, we can avoid depending on any single algorithm, optimize objectives and effects on a case-by-case basis, and incorporate multifaceted perspectives. Furthermore, introducing the Evidence Layer will bring validity, fairness, transparency, accountability, and persuasion, allowing people to actually benefit from those multifaceted perspectives. By overlaying different angles onto the technical philosophy of Plurality, Plurality can grow into a more resilient and inclusive concept.
Conclusion
Based on the discussion above, EBP, including impact evaluation, is essential for the sustainable development of digital public goods. As mechanisms for “creating, communicating, and utilizing” evidence are built out within EBP, the digital public goods ecosystem will grow more sustainably and pluralistically. Moreover, by becoming able to apply scientific knowledge in practice, fairness and persuasion in policies can be enhanced under diverse perspectives and values. The Evidence Layer constructed through protocols such as MUSE and Hypercerts is not merely a technical foundation; it is the basis for forming social consensus on the fundamental questions of “why, what, and how to support.” Establishing the Evidence Layer can make the future of digital public goods more reliable.
We welcome donations from those who wish to support our work. Your contribution helps us continue our research and development.
Support us via:
- Fiat (Credit Card): https://beaconlabs.io/support/
- Crypto: supports.beaconlabs.eth
If you’re interested in building the Evidence Layer or developing MUSE, please contact Beacon Labs!
Get Involved:
Footnotes
Beacon Labs. (2025). Impact Evaluation Landscape. https://beaconlabs.io/reports/impact-evaluation-landscape/ ↩
Beacon Labs. (2025). Harnessing Evidence: Applying Evidence-Based Practice to the Crypto Space. https://beaconlabs.io/reports/harnessing-evidence-applying-evidence-based-practice/ ↩
TAKEO NAKAYAMA. (2010). EVIDENCE: CREATE, COMMUNICATE AND UTILIZE. https://www.jstage.jst.go.jp/article/jspfsm/59/3/59_3_259/_article/-char/en ↩
Beacon Labs. (2024). A Retrospective Quantitative Review of Crypto Grants Programs. https://beaconlabs.io/reports/a-retrospective-quantitative-review-of-crypto-grants-programs/ ↩
Optimism. (2021). Retroactive Public Goods Funding. https://medium.com/ethereum-optimism/retroactive-public-goods-funding-33c9b7d00f0c ↩ ↩2
Paul J. Gertler, Sebastian Martinez, Patrick Premand, Laura B. Rawlings, Christel M. J. Vermeersch. (2016). Impact Evaluation in Practice. https://documents1.worldbank.org/curated/en/823791468325239704/pdf/Impact-evaluation-in-practice.pdf ↩
Beacon Labs. (2025). Beacon Labs: Beacon for Pluralistic Public Goods Funding. https://beaconlabs.io/reports/beacon-labs/ ↩
Old School Mathematicians (Too Old School). (2025). Quadratic funding under constrained budget is suboptimal. https://www.researchretreat.org/papers/paper/?venue=ierr25&id=4 ↩
Beacon Labs. (2024). Instrumentalized Plurality: Dialectic of Enlightenment fixes Plurality. https://beaconlabs.io/reports/instrumentalized-plurality-dialectic-of-enlightenment-fixes-plurality/ ↩